
Acquiring the desired font for various design tasks can be challenging and requires professional typographic knowledge. While previous font retrieval or generation works have alleviated some of these difficulties, they often lack support for multiple languages and semantic attributes beyond the training data domains. To solve this problem, we present FontCLIP – a model that connects the semantic understanding of a large vision-language model with typographical knowledge. We integrate typographyspecific knowledge into the comprehensive vision-language knowledge of a pretrained CLIP model through a novel finetuning approach. We propose to use a compound descriptive prompt that encapsulates adaptively sampled attributes from a font attribute dataset focusing on Roman alphabet characters. FontCLIP’s semantic typographic latent space demonstrates two unprecedented generalization abilities. First, FontCLIP generalizes to different languages including Chinese, Japanese, and Korean (CJK), capturing the typographical features of fonts across different languages, even though it was only finetuned using fonts of Roman characters. Second, FontCLIP can recognize the semantic attributes that are not presented in the training data. FontCLIP’s dual-modality and generalization abilities enable multilingual and cross-lingual font retrieval and letter shape optimization, reducing the burden of obtaining desired fonts.
We finetune a pretrained CLIP model with an existing font-attribute dataset to obtain FontCLIP. During each finetuning iteration, we randomly select attributes based on their scores from the font-attribute dataset and create a compound descriptive prompt for each font. Simultaneously, we generate a font image and apply a random augmentation transformation to enhance variability. We finetuned the last three transformer blocks (highlighted in red) for both encoders using a pairwise similarity loss function.

The system calculates the cosine distance between the input text prompt or image and the image of each font in the database, and then the sorted fonts are returned.

You can retrieve desirable fonts by inputting either a text prompt, an image, or a combination of both.
Thanks to the generalibility of FontCLIP, you can do a cross-lingual font retrieval, which means you can input an image of non-Roman letters to retrieve Roman fonts, and vice versa.
The initial letter in SVG format is rendered to a bitmap differentiably and input into the FontCLIP image encoder to calculate the distance between the latent vector and the reference latent vector that is obtained from a reference text prompt or image. The parameters of bezier curves in the input letter are repeatedly optimized by backpropagating the loss, which is the sum of the distance in the FontCLIP latent space and other constraints to preserve the initial letter shape.




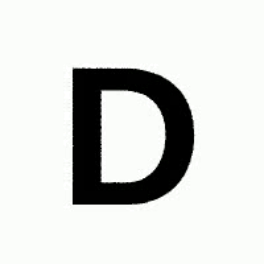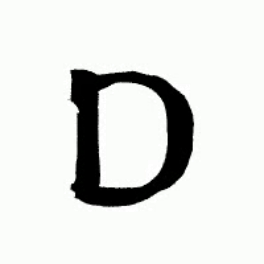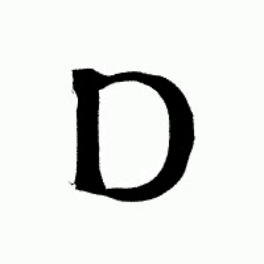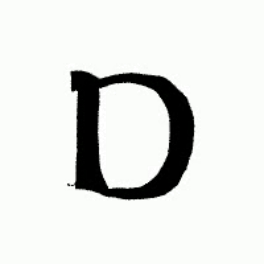
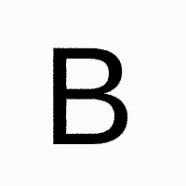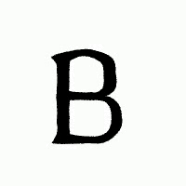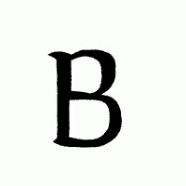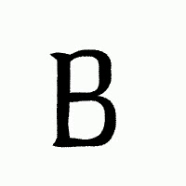




@article{tatsukawa2024fontclip,
author = {Tatsukawa, Yuki and Shen, I-Chao and Qi, Anran and Koyama, Yuki and Igarashi, Takeo and Shamir, Ariel},
title = {FontCLIP: A Semantic Typography Visual-Language Model for Multilingual Font Applications},
journal = {Computer Graphics Forum},
year = {2024},
}